自然言語処理の続きなのですが、ひと昔前、ニューラル機械翻訳では自然言語処理で紹介したRNNベースのsequence-to-sequenceが用いられていました。この時もAttentionというメカニズムは使われていましたが、2017年にGoogleから発表された論文 “Attention is All you need”では、AttentionだけでかつてのRNNの性能を大きく上回る機械翻訳精度を達成し、今では自然言語処理分野の技術は、ほぼAttentionベースの技術(Transformer, BERT, GPT等)が主流となっております。
このGoogleから発表されたAttentionベースのニューラル機械翻訳技術がTransformerです。BERTやGPTも、このTransformerの仕組みと共通しているので、このTransformerの理解が自然言語処理の分野では最重要だと思います。
RNNのAttention
では、まず Transformerで重要となる Attentionについて説明します。このAttentionは、従来のRNNベースの機械翻訳でも使われているため、まずRNNベースで、Attentionとは何なのかを説明します。
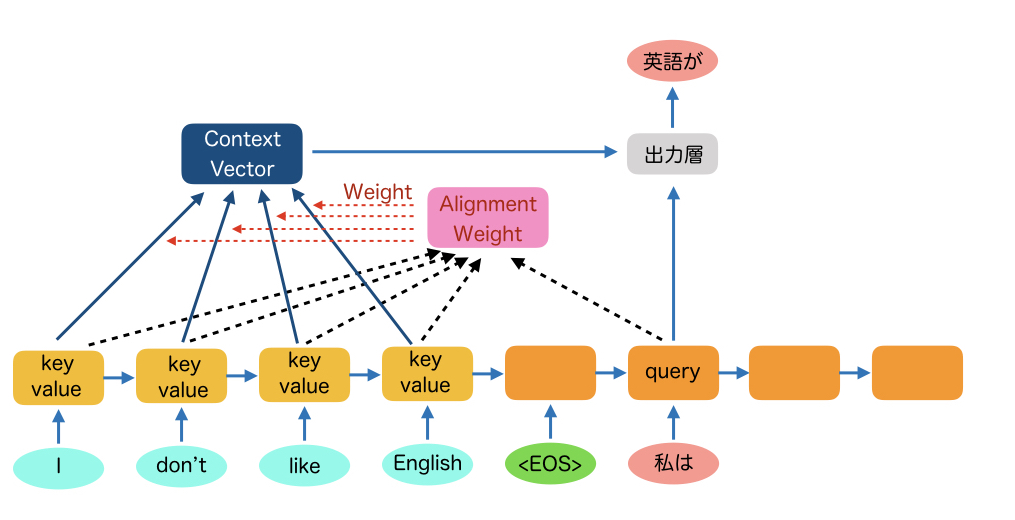
RNNの内部状態だけだと、最初の方で入力した単語の情報ほど情報が薄くなっていってしまいます。Attentionとは、デコーダで出力する単語が、エンコーダの入力単語のどの単語を注目すれば良いかを示す指標になります。これは、デコーダ側で所定の位置の単語の内部状態において、エンコーダ側の各入力における内部状態との相関(類似度)を計算し、各入力単語の内部状態に重みをつけて合算し、Context Vectorをいうものを作ります。このContext Vectorをデコーダの出力層に入力し、出力単語の尤度計算に影響させることで、Attentionを考慮したsequence-to-sequenceが可能になります。
このAttentionメカニズムは、query, key, valueに分けて説明されることが多いです。上のRNNの場合、queryはTarget側のベクトルになります。keyとvalueはSource側のベクトルになります。
まず、queryと各keyの内積をとってSoftmaxで正規化したものがAlignment Weightというベクトルになります。これはTarget側の所定の位置の単語が、どの入力単語と相関が高いかを示し指標です。
次に、そのAlignment Weightと各valueを掛けたものが、Context Vectorとなり、デコーダの出力層に影響を与えます。相関が高い単語ほど大きく影響を与えることができるようになります。
TransformerのAttention
では、Transformerの説明に入ります。TransformerはRNNのように前の入力の内部状態を引き継いでいく構造では無いです。すべてAttentionでの計算になります。エンコーダ側もしくはデコーダ側だけでAttentionを計算するものを Self Attentionといいます。また、RNNの時と同じように、デコーダの所定の位置の計算にエンコーダのAttentionを計算するものを Source Target Attentionといいます。
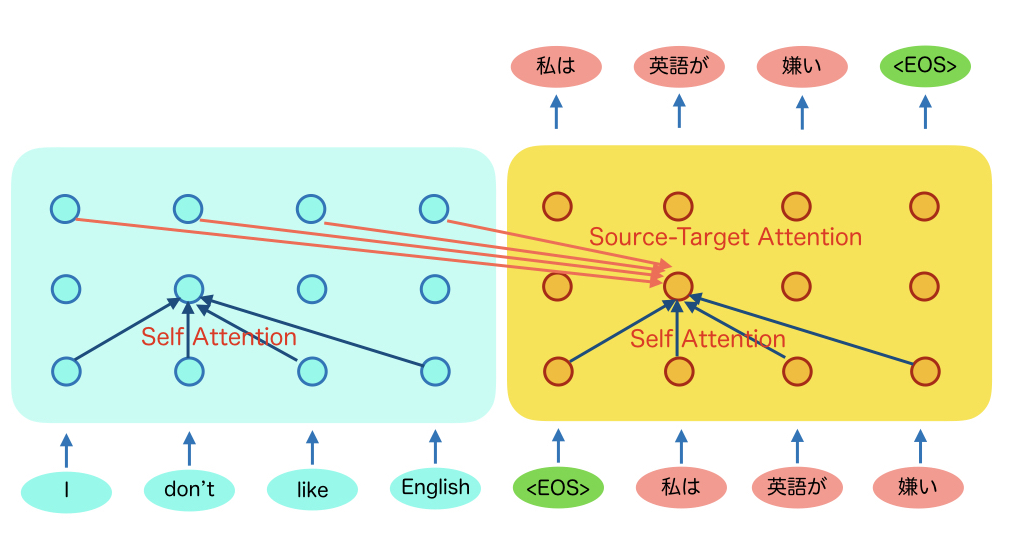
Self Attentionは、上の図だと、ある層において、各ポジションごとに他の入力とのAttention Weightを計算し、上の層の内部状態を計算するようになっています。
Source-Target Attentionは、基本的にエンコーダの最後の層(一番上)の内部状態を使います。こちらはRNNと同じようにAttentionを計算し、デコーダの次の層(上の層)を計算していきます。デコーダの最終層(一番上)から、出力単語を推定します。
RNNを使わないと、もはや語順とか関係ないんじゃないかと思うかもしれませんが、入力の部分にポジションエンコーディングという機構があり、この単語は全体の何番目に入力された単語かを示すベクトルが付与されています。
Transformerの全体の構成を論文から引用します。
左側がエンコーダで右側がデコーダになってます。それぞれN層積んで構成されます。この中で新たにでてくるのが、Masked Attentionと、Multi-Head Attentionかと思います。
Masked Attentionとは、デコーダでは未来の単語がわからない状態で推定しなければいけないため、未来の単語へのAttentionは使わないという意味でMaskします。
Multi-Head Attentionですが、TransformerはAttentionしか使わないので、Attentionを全体で行うと入力文章の意味をあまり理解せずに、単にエンコーダの単語からカンニングするような翻訳がでてしまう可能性があるため、エンコーダの単語群をいくつかのグループにわけて、いろんな視点からAttentionを計算することにより、単なるカンニングよりも深い翻訳ができるようにしているイメージです。
以上がTransformerの概要ですが、最近、大規模言語モデルとして注目されているBERTやGPTも、このTransformerがわかると理解できます。(というかTransformerの一種という位置付けです)BERTは、Transformerのエンコーダ部分で構成されており、文書分類、ラベリング等、さまざまな言語処理が可能です。GPTは、Transformerのデコーダ部分だけで構成されており、デコーダの先頭に文章を入れることで、その続きを生成してくれます。