私たち人間が扱う言語をコンピュータで処理することを自然言語処理といい、言葉の意味を理解したり、言葉を生成したりと、 まるで人間のようなことができるようになります。
言語処理で重要になってくるのは、単語をベクトルとして扱うところだと思います。word2vec等、単語を数値のベクトルに変換することで、 単語同士の演算処理ができるようになります。よくある例の、「王様」ー「男」+「女」=「女王」、というような演算もできるようになります。
では、まずどうやって単語をベクトル化しているのかですが、代表的なものとしては、CBoW (Continuous Bags of Words) と Skip-Gramという 2種類の方法があります。どちらもニューラルネットワークを使うものですが、Skip-Gramの方が精度が良いのと、直感的にもわかりやすいため、 ここでは、Skip-Gramの例を説明します。
図1にSkip-Gramで、単語ベクトルを学習する例を書きました。
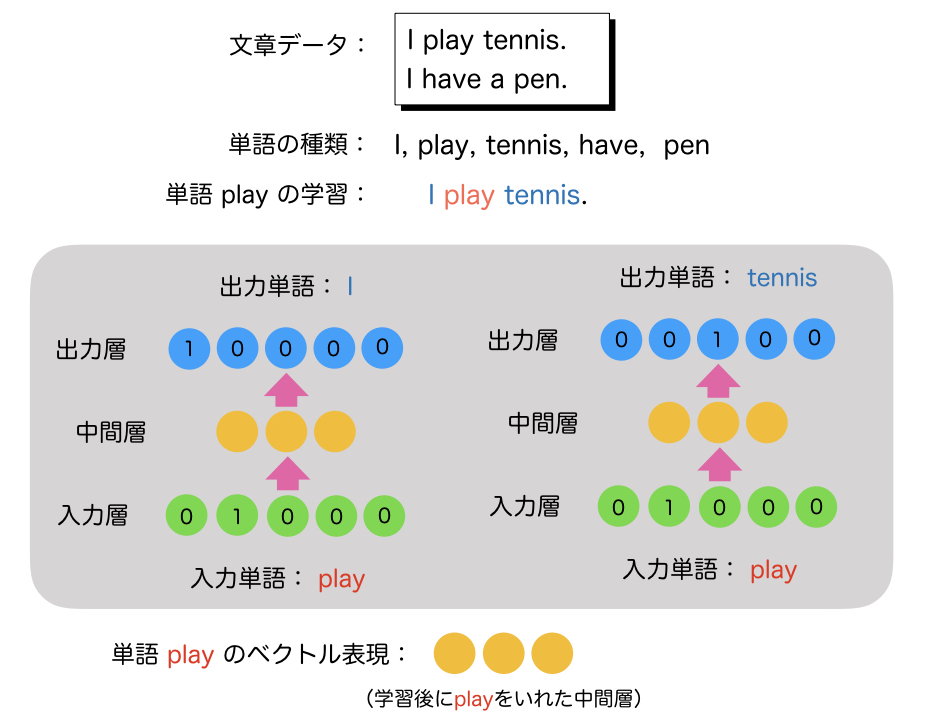
この例では、”I play tennis.” と “I have a pen.” という2つの文章だけが学習データです。この学習データの中に登場する単語は、 I, play, tennis, have, pen の5種類です。(aは省略しました)この言語には5種類の単語しか無いという前提になります。(例ですので)
Skip-Gramでは、入力層にある単語を入れて、その単語付近にある単語が出力層に出やすくなるように学習させます。つまりその単語と関係性の高い単語を 出力するようにします。この例では、playという単語を入れていますが、playの近くにある単語は、Iやtennisです。これは、playは、私(人)が することであるとか、playは、tennis(スポーツ)をすることであるとか、そういうことを学んでいくわけです。一方、penは、playの付近にはでてこないので penとは関係性が低いということも学びます。
どうやって学んでいるかですが、まずこの言語は5種類の単語しかないので、単語を5次元のone-hotベクトルに変換します。one-hotベクトルとは、要素のうち ひとつが1であとは全て0というベクトルで、例えばplayという単語であれば、playがこの言語の辞書の2番目にあるので、 2番名の要素だけが1、あとは全て0というベクトルになります。(これは単語ベクトルとは違います)
出力の単語も同様のone-hotベクトルを用い、Iであれば1番目だけが1、tennisであれば3番目だけが1のベクトルになります。 そして、playを入れたらIやtennisがでやすいようにニューラルネットワークを学習させていきます。 (例なので5次元ですが、実際は50000次元ぐらいが使われます。単語の種類の数だけ次元数が必要になります。)
中間層は、one-hotベクトルではなく、普通に各要素にさまざまな実数が入ります。この例では3次元のように書いていますが、 実際は100次元〜300次元ぐらいが使われます。
そして、単語ベクトルとして使うのは、この中間層のベクトルになります。出力層は学習させるためだけに使い、単語ベクトルを 生成する時は使いません。学習後のネットワークで、playを入力層に入れて計算した中間層のベクトルが単語ベクトルになります。
これがSkip-Gramの概要です。実際には出力として学習させる単語は、入力単語の隣だけではなく、前後5単語ぐらい使います。
CBoWは、Skip-Gramの入力と出力が逆になったものです。ターゲット単語の周辺の単語を入力とし、そこからターゲット単語を 出力するためのネットワークを作ります。
このように単語をベクトル表現することが、言語処理の基本となってきます。この単語ベクトルを使った言語処理の例を2つご紹介します。
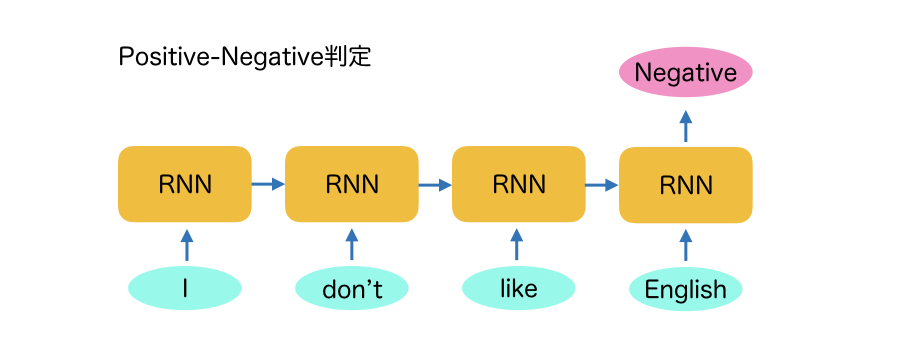
1つ目は文書分類のリカレントニューラルネットワークです。これは、入力した文章がどういうカテゴリのものかを分類するため等に使われます。
図2に、文章がPositiveなのかNegativeなのかを判定する文書分類の例を示します。
この例では、”I don’t like English.”という文章が、PositiveなのかNegativeなのかを判定するRNN(リカレントニューラルネットワーク)の例で、 まず、単語に分割し、I, don’t, like, English という単語を順番にRNNに入力していきます。この時にもこれらの単語はone-hotベクトルから 単語ベクトルに変換されます。(Word Embeddingと言われます)
そして、最後の単語が入力された時に出力層をPositiveとNegativeの2値の要素として、どちらが大きいかで判定します。学習時はあらかじめ ラベルが降ってあるので、Positiveであれば、Positiveの要素を1、Negativeの要素を0として学習させます。
2つ目はSequence-to-Sequenceのリカレントニューラルネットワークです。文章を入力すると、文章が出力されるというものです。
図3に、機械翻訳の例を示します。
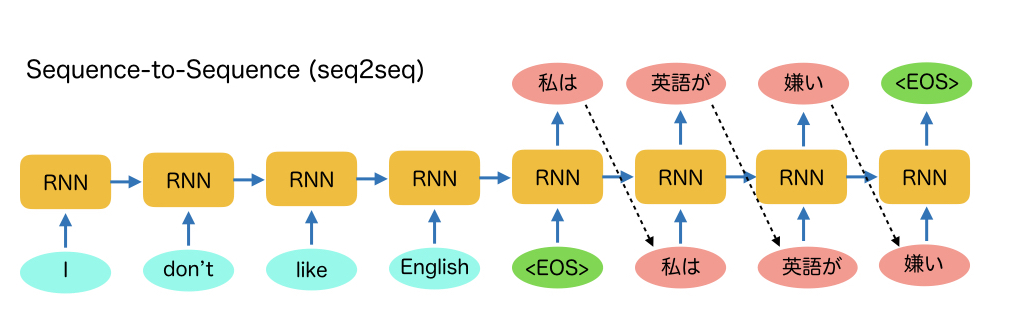
この例では、先ほどと同様に、”I don’t like English.”という文章を単語ごとにRNNに入力していきます。そして、文章の終わりを示すEOSという 単語が入力されると、この文章の日本語訳の先頭の単語である「私は」という単語の尤度が高い単語ベクトルを出力します。 そして、次に「私は」という単語を次のRNNの入力層に入力します。そうすると、日本語訳として「私は」に続く単語を推定し、「英語が」という 単語ベクトルを出力します。
このような処理をEOSという単語がでるまで続けると、日本語訳の「私は 英語が 嫌い」という文章が生成されています。
単語をベクトル表現できると、このような処理が実現できるようになり、文章の判定や、文章の生成も可能になります。 使い方次第で、いろいろなことができそうですね。