Angularとは、フロントのSPA (Single Page Application)のアプリ開発をする際に重宝するフレームワークでして、コンポーネント単位で開発でき、ルーティング機能もあるため、レスポンスの速い快適なアプリケーションが開発できます。(他にreactやVue.js等もあります。)
なぜ、Angularなどのフレームワークがレスポンスが速いのかは、以前に書いたreactのページで記載しました。基本的にはAngularも同じです。
ここでは、Angularのインストール・環境構築から、簡単なWebサイトの作成までをご説明します。
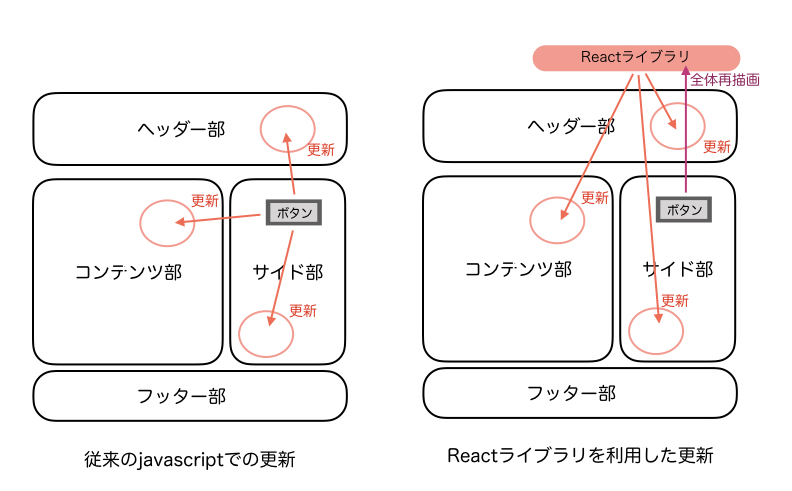
よくある、下記のようなレイアウト構成のページをコンポーネント単位で作成し、コンテンツをサイドメニューから切り替えることができるようにします。これだけでもレスポンスが速いのがわかると思います。
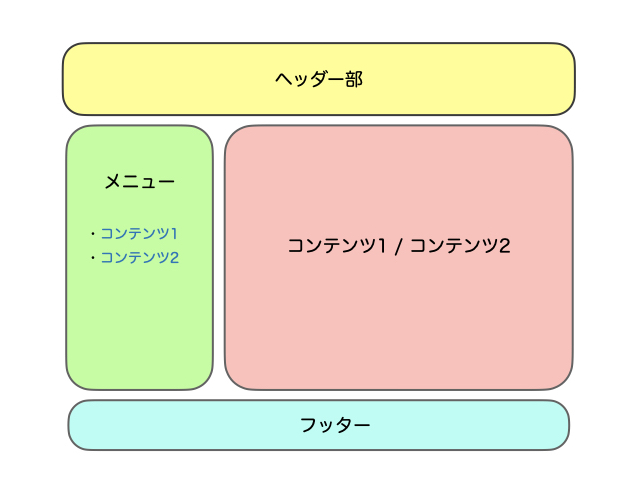
では早速、作っていきましょう。
Angularのインストールと環境構築
まず、Angular CLIをインストールするのですが、npmコマンドでインストールしていくため、もしnpmコマンドが無い場合は、下記のnodeのページからNode.jsをダウンロードしてインストールすれば、npmも入ります。
まずは、Angular CLIをインストールします。
# npm install -g @angular/cli
これだけで基本的にはAngularのインストールは完了です。ですが、レイアウトや便利部品などを使うためにmaterialは必須になってきますし、フォームやhttp通信をする場合も別途モジュールを追加していく必要がありますので、ここでは、materialというモジュールを追加してみます。
まず、Webサイトのアプリケーションを作成します。(この中でモジュールを追加していくので)
sampleというアプリケーション名にします。
# ng new sample
これで、sampleというフォルダができたと思います。この中に入ります。
# cd sample
materialのモジュールを追加します。
# ng add @angular/material
そして、src/app/app.module.ts に、materialの中のMatGridListModuleというモジュールを使うことを書きます。
import { MatGridListModule } from '@angular/material/grid-list';
同ファイルのNgModuleの中にも追加します。
imports: [
BrowserModule,
AppRoutingModule,
MatGridListModule
],
これで準備完了です。
コンポーネントの作成
次に、ヘッダ、メニュー、コンテンツ1、コンテンツ2、フッターのコンポーネントを作っていきます。コンポーネントを作るときも、コマンドラインで作ります。
# ng generate component header # ng generate component menu # ng generate component content1 # ng generate component content2 # ng generate component footer
そして、src/app/app.component.htmlを下記のように書き換えます。最初に何かたくさん書いてありますが、全部消して大丈夫です。
<app-header></app-header>
<mat-grid-list cols="4" rowHeight="50px">
<mat-grid-tile colspan="1" rowspan="6">
<app-menu></app-menu>
</mat-grid-tile>
<mat-grid-tile colspan="3" rowspan="6">
<app-content1></app-content1>
</mat-grid-tile>
</mat-grid-list>
<app-footer></app-footer>
まずは、コンテンツ1(content1)だけを表示します。何をやっているのかというと、全体を4つの列に分けて(cols=”4″)、menu部分を1列分(colspan=”1″)、content1部分を3列文(colspan=”3″)にして表示しています。
では、ここまでのソースコードをブラウザに表示して確認してみます。apacheやnginx等のWebサーバで動かすこともできるのですが、手っ取り早く確かめるには、違うポートでAngularのWebサーバを立ち上げて確認します。
# ng serve --port 8080
これで、localhostの8080番ポートでこのサイトが見れるようになりましたので、ブラウザで、http://localhost:8080/ にアクセスしてみましょう。
header works!や、menu works!、content1 works!、footer works!が表示されていればできています。
Routerでページ切り替え
では、次にメニュー部分にリンクを作成し、コンテンツ部をcontent1とcontent2で切り替えられるようにします。
まず、content1を表示させていた部分をrouterで切り替えられるようにします。
先ほどの src/app/app.component.htmlの中のcolspan=”3″の中を書き換えます。
<mat-grid-tile colspan="3" rowspan="6">
<div class="main">
<router-outlet></router-outlet>
</div>
</mat-grid-tile>
次に、menu部分のコンポーネントのhtmlを作成します。src/app/menu/menu.component.htmlに下のように書きます。
<ul> <li><a routerLink="/content1">コンテンツ1</a></li> <li><a routerLink="/content2">コンテンツ2</a></li> </ul>
リンク部分が href ではなく、routerLink になっております。AngularのRouter機能を使ってページを切り替えるためです。ですが、このままだとRoutingされませんので、もう少し設定します。
src/app/app-routing.module.ts を下のように追記します。
import { Content1Component } from './content1/content1.component';
import { Content2Component } from './content2/content2.component';
Routesの変数にも追記します。
const routes: Routes = [
{ path: '', redirectTo: '/content', pathMatch: 'full' },
{ path: 'content1', component: Content1Component },
{ path: 'content2', component: Content2Component }
];
これでもう一度、ブラウザで確認してみましょう。
先ほどのng serveが立ち上がったままでしたら、すでにブラウザに自動で反映されていると思います。止めていたら、再度同じように立ち上げましょう。
メニュー部分に、「コンテンツ1」と「コンテンツ2」のリンクができていて、クリックすると、それぞれ、コンテンツ部が content1 works!とcontent2 works!に切り替えられたらできています。
ページのリロード無しで切り替えられるため、速いです。(コンテンツがこれだけだとあまりわからないかもしれませんが)
Webサーバで見れるようにする
ここまでは、ng serveコマンドで8080番ポートに簡易なWebサーバを立ち上げて確認していました。ですが、実際にデプロイするときには、apacheやnginxなどの既存のWebサーバのどこかのフォルダに置きたいと思います。そのための作法についても説明します。
まず、Webサーバにデプロイするためには、ソースコードをビルドする必要があります。この時に、この作成したWebページを、Webサーバのどのフォルダに置くかを決める必要があります。ドキュメントルートからの相対的なパスで指定します。
例えばローカルホストのサーバで、
http://localhost/sample/
という場所で見れるようにするには、相対パスが /sample/ ということをビルド時に指定します。
# ng build --base-href=/sample/
これでビルドされて、ワークスペースの dist/ というフォルダに sampleというフォルダができています。これをこのまま、Webサーバのドキュメントルートにコピーすれば、上記のURLで見れるようになります。
apacheの場合は、/var/www/html がドキュメントルートの可能性が高いです。