機械学習の学習ってGPUが必須だと思いますが、個人や会社でGPUマシンが無い場合は、クラウドのGPUインスタンス等を使う必要があります。GPU使っても2〜3日かかる学習などもあると思いますので、結構GPUインスタンス代が馬鹿になりません。立ち上げてるだけで料金が発生しますので、学習終わったら、一刻も早くインスタンスを終了させたいです。
Lambda等で自分で作成して、GPUインスタンスの起動、学習、停止まで一連のプロセスを自動化することもできますが、そういうのをやってくれるSageMakerというAWSのサービスがありますので、SageMakerを紹介します。
SageMakerとは
SageMakerとは、データさえS3に用意すれば、機械学習を誰でも簡単にできるようなサービスです。TensorflowやMXnetなどのコンテナも用意されており、それらを使うなら環境構築など面倒なことを一切やらず、起動、データ入力、学習、モデル出力、停止まで簡単に実現できます。
ですが、やっぱり既存のコンテナには無い機能やライブラリを使っていたり、フレームワーク自体を改造していたりすることを往々にしてあると思います。ここでは、独自のコンテナを使ってSageMakerを利用し、一連の処理を実行する例を紹介します。
独自コンテナを使う場合の利用方法
まず全体の流れですが、下の図のような感じになります。
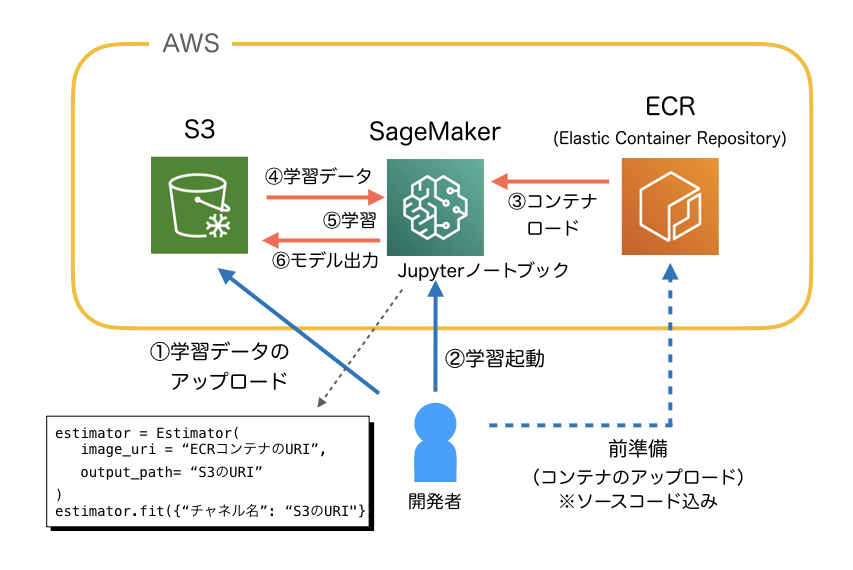
前準備としては、学習用のソースコードも含めたコンテナをECR(Elastic Container Repository)にアップロードしておく必要があります。SageMakerからロードして使います。
学習時にユーザ(開発者)がやることとしては、
- 学習データをS3にアップロードする。
- SageMakerのJupyterノートブックで、学習スクリプトを実行する。
これだけです。これで、自分のコンテナがロードされ、その中で学習データが学習され、モデルがS3に出力されます。
学習の起動は、SageMakerのJupyterノートブックインスタンスで行うのですが、ここに、ロードするコンテナのURIや、学習データのS3 URI、出力モデルのS3 URIを記載して fit()すると全部自動でやってくれます。
独自コンテナの作り方
では、コンテナはどのように作っておけばいいかなのですが、少しだけSageMaker的ルールがあります。
ルール1
学習時には、docker run image trainコマンドが実行される。つまりコンテナ内で trainコマンドを自作し、実行権限をつけてPATHを通しておかなくてはいけない。
ルール2
学習データは S3から、コンテナ内の /opt/ml/input/data/チャネル名 にダウンロードされて上記 trainコマンドが実行される。つまり、このパスにあるデータを学習するように作っておく必要がある。
ルール3
学習終了時には、/opt/ml/model 以下のファイルをS3にアップロードする。つまり、生成したモデルをここに置く必要がある。
以上のルールを考慮してコンテナを作ります。ルール1のtrainコマンドのPATHですが、/opt/program/train に置くのが良いのですが、それでもPATHを設定していないとエラーになります。なので、コンテナをbuildする時のDockerfileで設定します。
Dockerfileの例
FROM ベースとなるイメージ
SHELL ["/bin/bash", "-c"]
WORKDIR /opt/program
ENV PATH="/opt/program:${PATH}"
このようなDockerfileを作ってPATHに /opt/programを通します。そして、
# docker build -t 生成するイメージ名 .
buildコマンドでイメージを作成します。上記のDockerfileのあるフォルダで実行します。そして、このイメージをECRにpushすればOKです。
Jupyterノートブックからの起動方法
SageMakerで学習を行うために、Jupyterノートブックインスタンスを使います。ここで学習用のコンテナを起動させるのですが、Jupyterノートブックインスタンスとは別のインスタンスとして立ち上げるため、ノートブックインスタンスはGPUインスタンスではなく、ml.t2.mediumなどで良いかと思います。
学習用のノートブックのスクリプトの概要です。
from sagemaker import estimator
from sagemaker import get_execution_role
bucket='S3のバケット名'
image_uri='ECRのイメージURI'
role = get_execution_role()
data_location = 's3://{}/input'.format(bucket)
output_location = 's3://{}/model'.format(bucket)
estimator = estimator.Estimator(
image_uri=image_uri,
role=role,
train_instance_type="GPUインスタンスのタイプ(ml.p2.xlargeなど)",
output_path=output_location
)
estimator.fit({チャネル名: data_location})
このようなスクリプトを書いて実行するだけで、/opt/ml/input/チャネル名にデータがコピーされ、あとは自動で学習をやってくれます。できたモデルはS3のバケットにアップロードされます。
SageMakerの使い所
ここまでの作業を自分ひとりでできて、自前でGPUも持っている方は、SageMakerを使う必要はほぼ無いと思います。ですが、誰か別の人や、他社の方に学習環境を提供する時などには、SageMakerはとても便利です。もちろん、自前でGPUを持っていない場合は、自分で使うのにも良いと思います。